How the SharedStreets Referencing System Works
By Emily Eros in Data Deep Dive · May 1, 2019
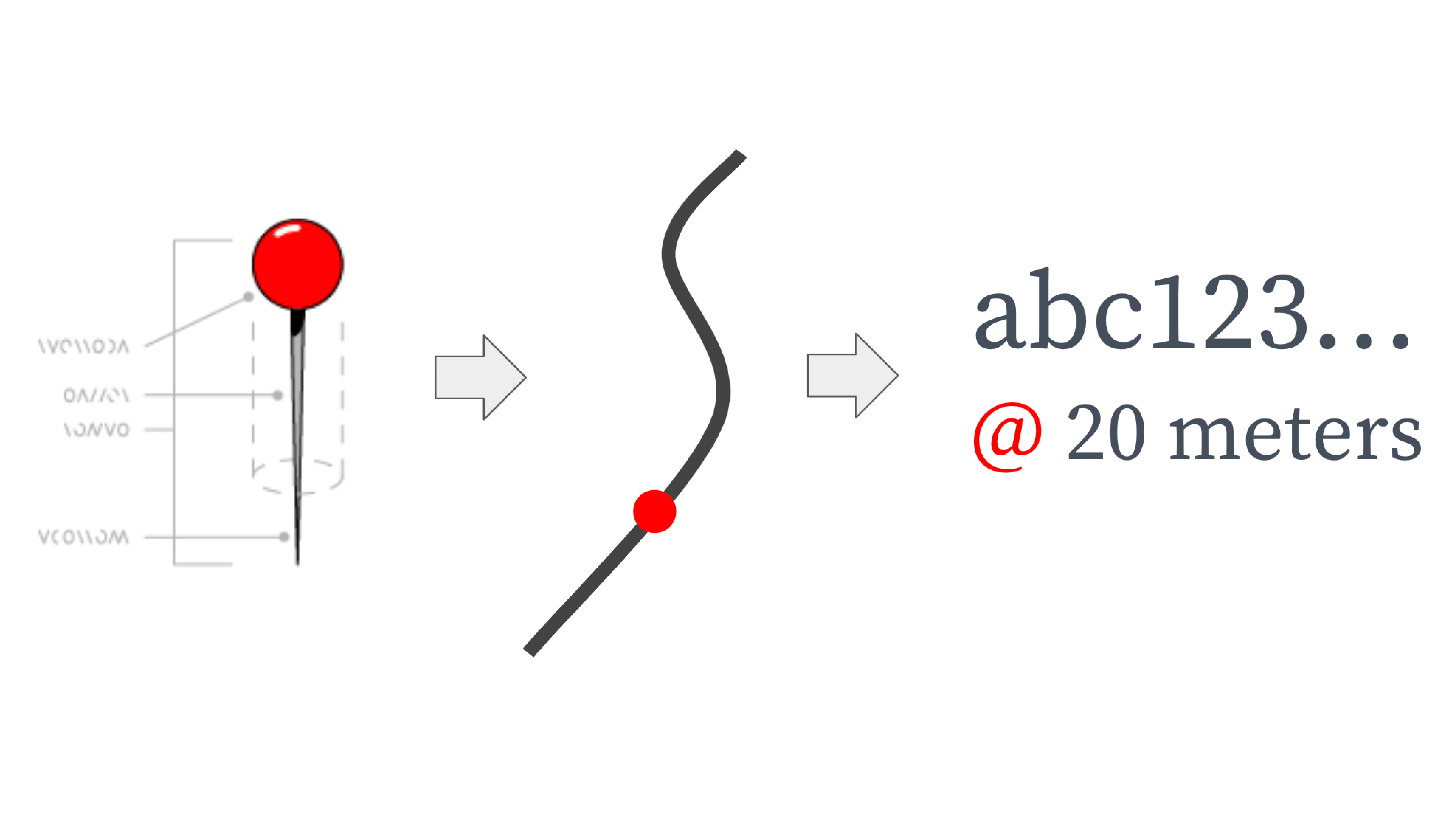
SharedStreets lets maps talk to one another by relying on a fundamentally different way of conceptualizing the street.
Typically, transport-related data is defined by spatial coordinates (like latitude and longitude) that describe the location of features. We also use attributes (like street names) that describe their properties. But transport systems are only quasi-geographic; the location of a street matters, but so does its role within the whole network of streets and intersections. That’s why it’s so hard to work with disparate datasets. For example, a city’s GIS file and a company’s speed dataset may have a different understanding of exactly where a street centerline is located, or exactly how to describe it (First Street, 1st Street, FIRST ST). The maps may be referring to the same thing, but they will never agree based on their coordinates or properties. Combining these datasets involves cumbersome and imprecise methods like spatial processing (buffers, spatial joins, and other proximity-based operations) or string-matching (joining by name or other attributes).
Instead of a geographic model, SharedStreets uses a “network dimensional” model. We conceptualize the street as a path that runs between two intersections at a certain bearing, defining it based on its role within the transportation network. The precise geometry doesn’t matter. The precise name and other fields don’t matter. We might have datasets that define the street in slightly different ways, but we can agree that we are talking about the same thing, and we can refer to it in a common way. Now, we have a shared language for the world’s streets.
Map Matching
Linear referencing makes it easy for different base maps to refer to each street in a common way. For each street, we determine the location of the start and end intersection, the bearing between these for the first 20 meters, and the length of the street.
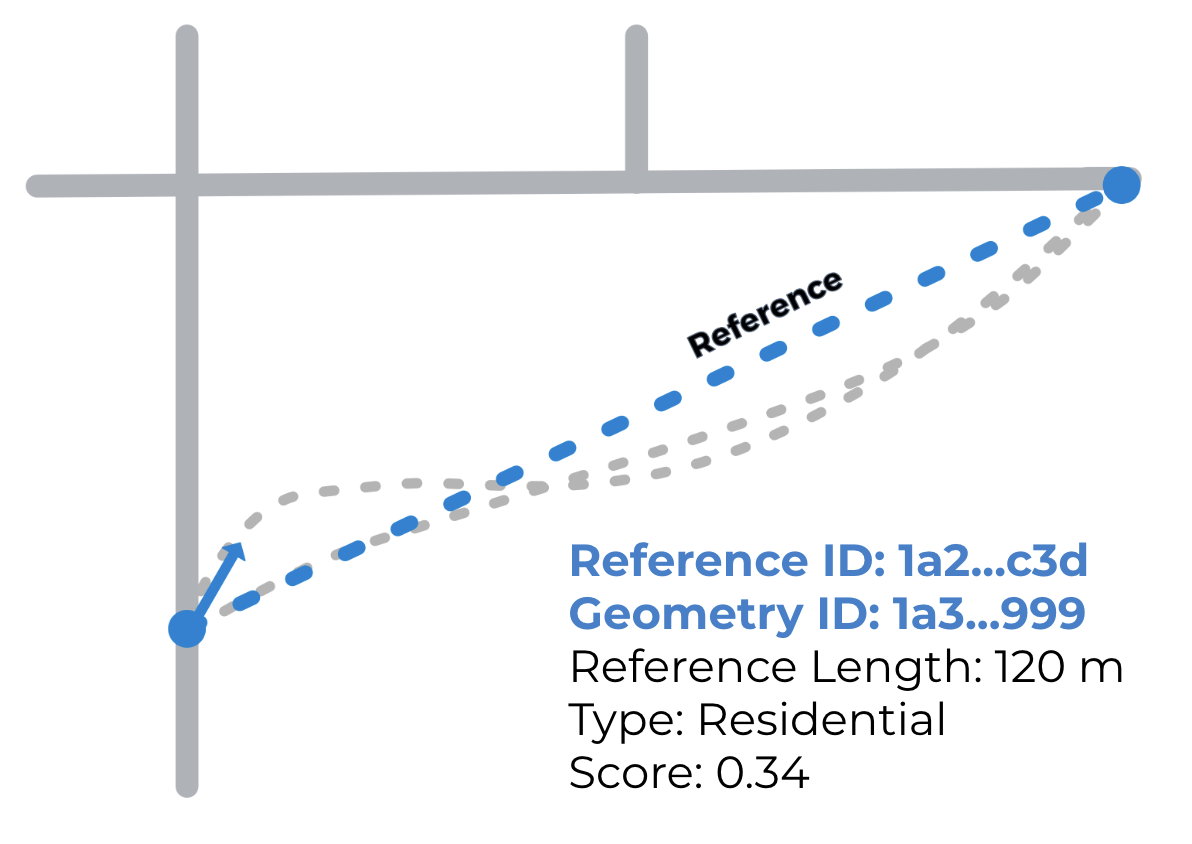
This is encoded in a Reference ID, which is a series of letters and numbers. The Reference IDs may seem arbitrary, but they are actually a format called a hash, which encodes geographic information - similar to latitude and longitude, but in a single field and with more detail. SharedStreets generates a global set of street reference IDs, using geometries from OpenStreetMap.
SharedStreets References are directional edges in a road network. Therefore, two-way streets have two Reference IDs, one for each direction of travel, while one-way streets only have one Reference ID. Each street also has a Geometry ID that encompasses both directions - similar to a street centerline.
We can then take other input datasets, like a city’s GIS centerlines, and match them to the SharedStreets reference dataset. As long as the streets are similar enough, they will match to the SharedStreets system and be assigned the same geometry ID and reference ID(s). These IDs can be used in any database or GIS software to easily link maps to one another so that data can be shared between them.

Matching point and segment data
Point data (like bike racks) and segment data (like parking zones) are matched in a similar way. The input data are matched to the nearest street and snapped to it at a 90-degree angle. The results include the SharedStreets Reference ID (SSRID) for each point, as well as its location along the street. Points include one location; line segments include the start and end location.
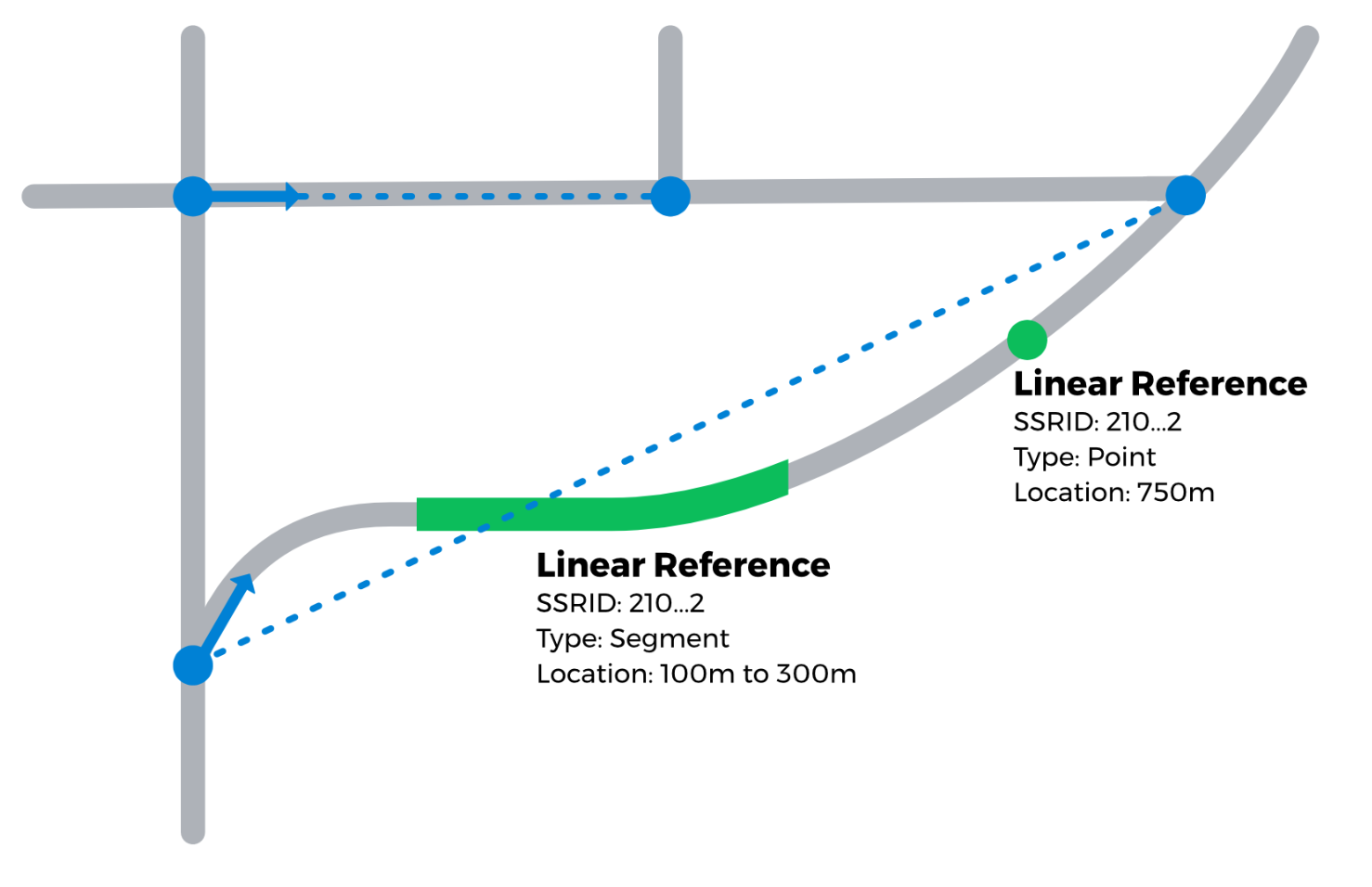
With these tools, users can take standalone datasets and link them to the street based on their location along it. Below is an example using an open parking dataset in the city of Seattle. The entire dataset has been matched using SharedStreets. Each feature’s Reference ID and start and end location can be used to link it to other datasets, like taxi and rideshare pick ups and drop offs, micromobility availability, and pedestrian infrastructure. This enables planners to analyze how space along the curb is allocated, how this space is being used, and whether the appropriate infrastructure is in place.

Matching lots of points or segments
Small datasets, such as bus stops or bike racks, can easily be matched using the basic method above. For larger datasets, binning and aggregation are used, according to the following method:
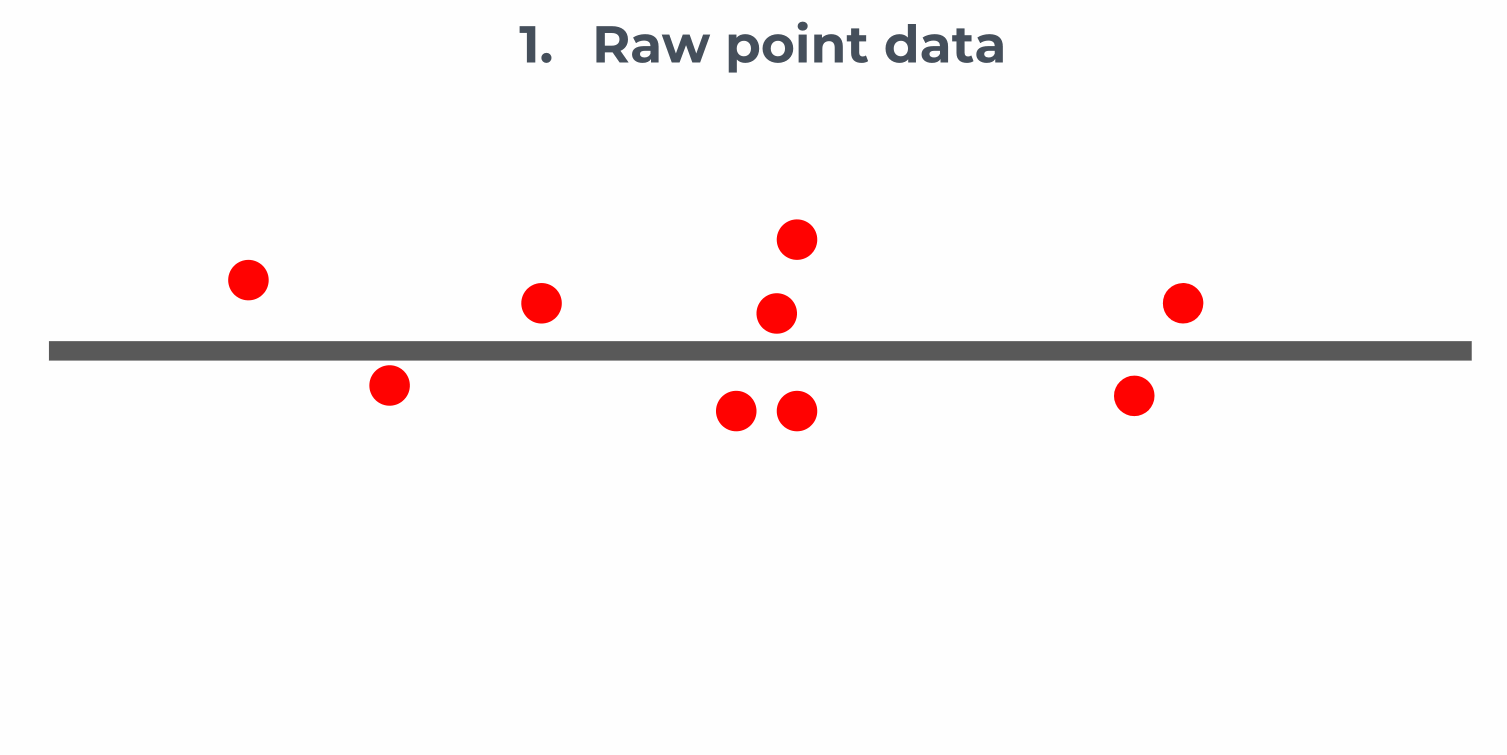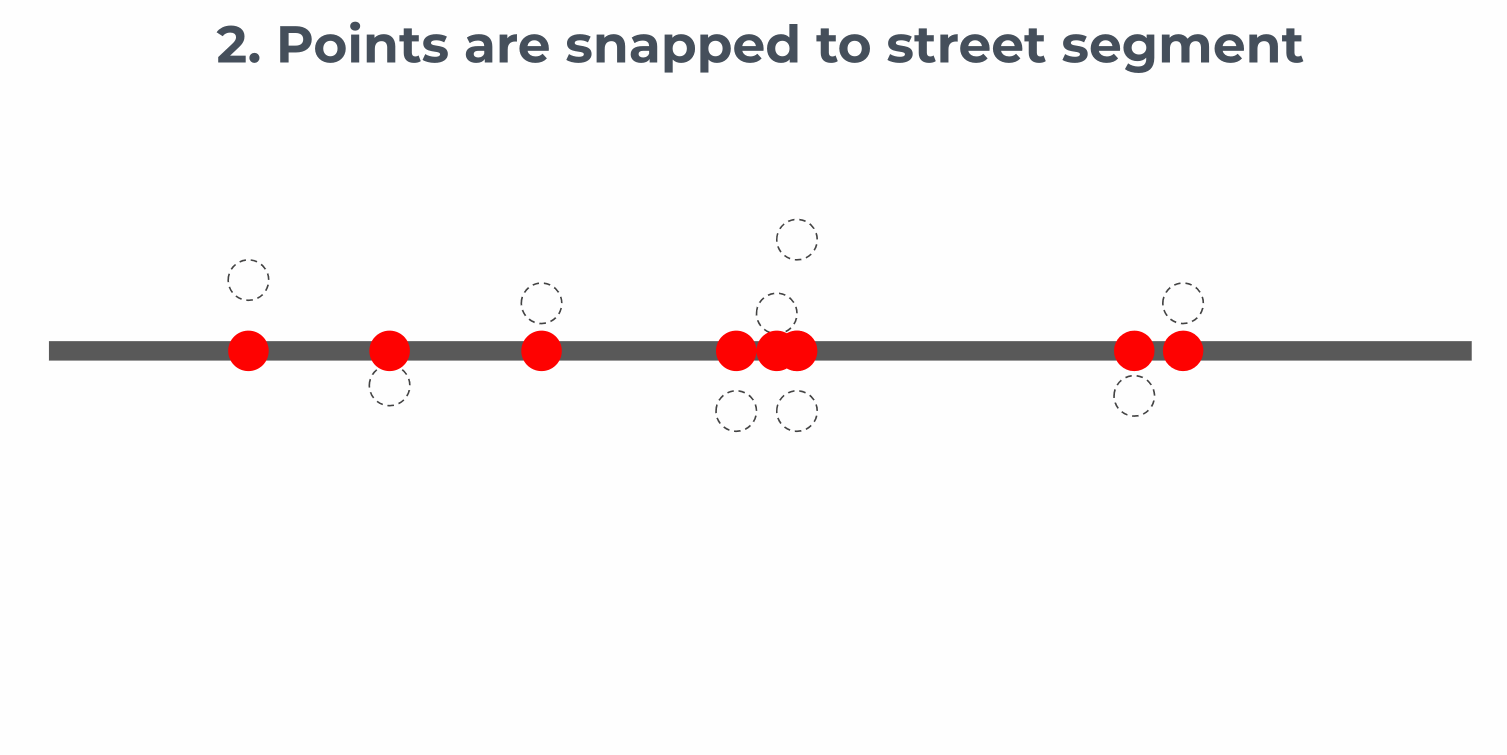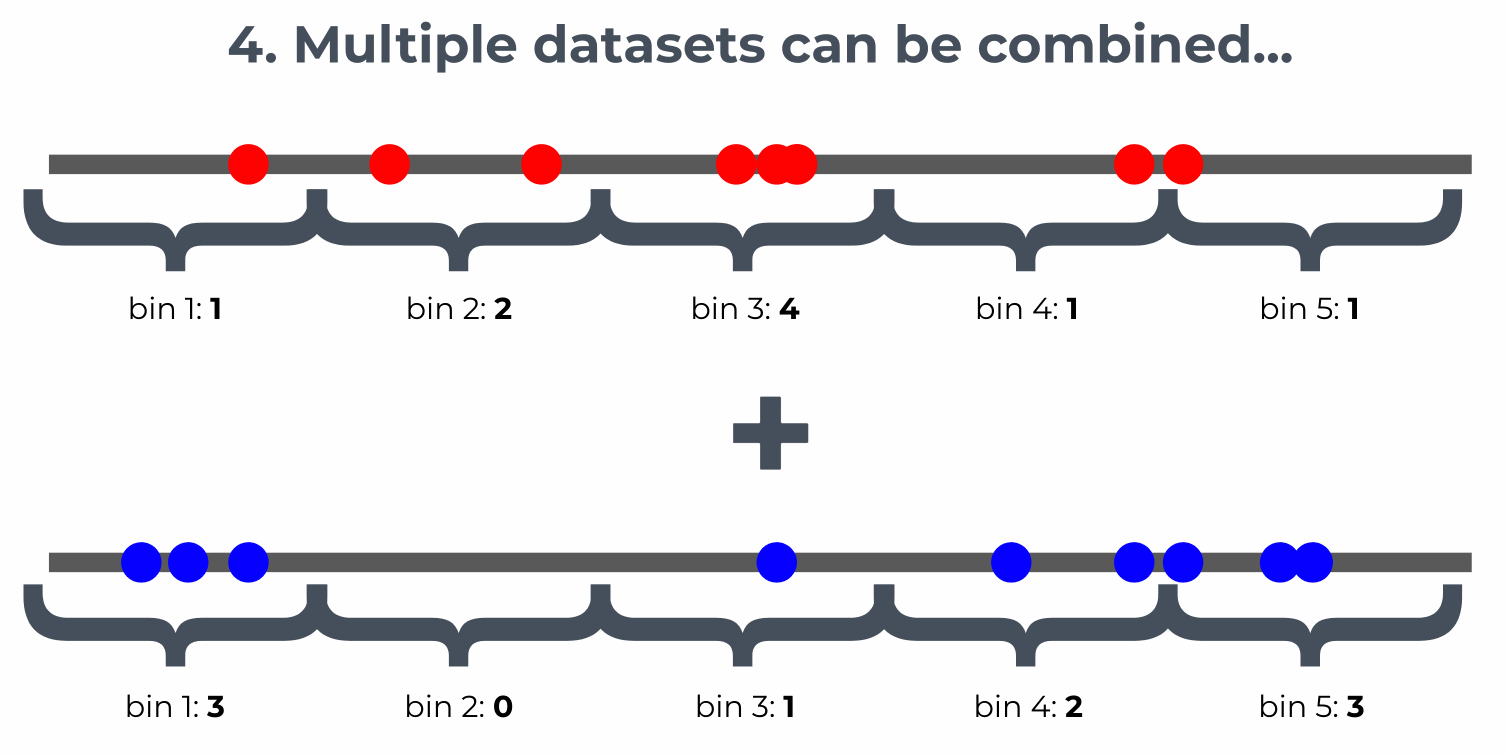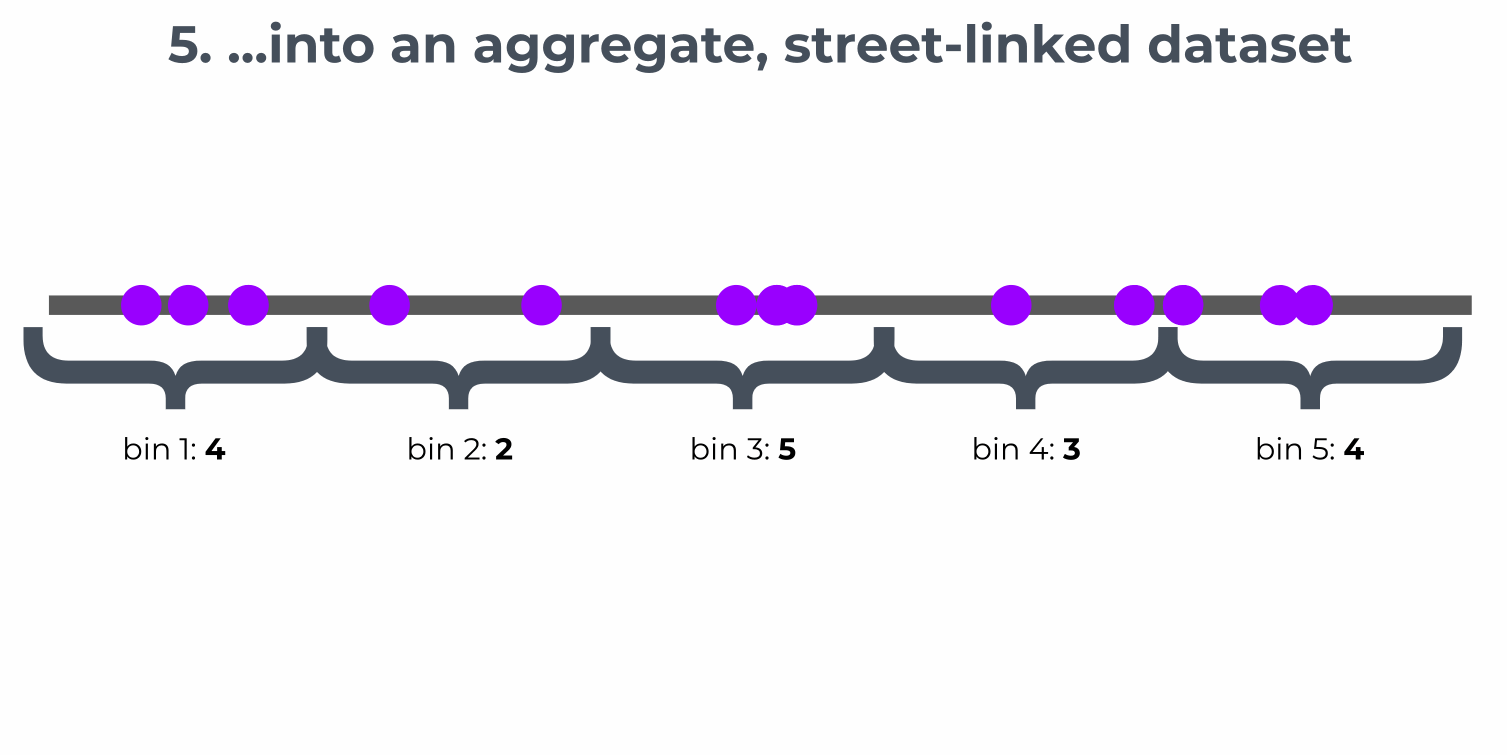
Users can set the approximate bin size and the matcher will divide streets into segments to achieve that target bin size. Results can be addressed using the SharedStreets Reference ID, the target bin size, and the bin’s position in the array. You can read more about our aggregation methods here.
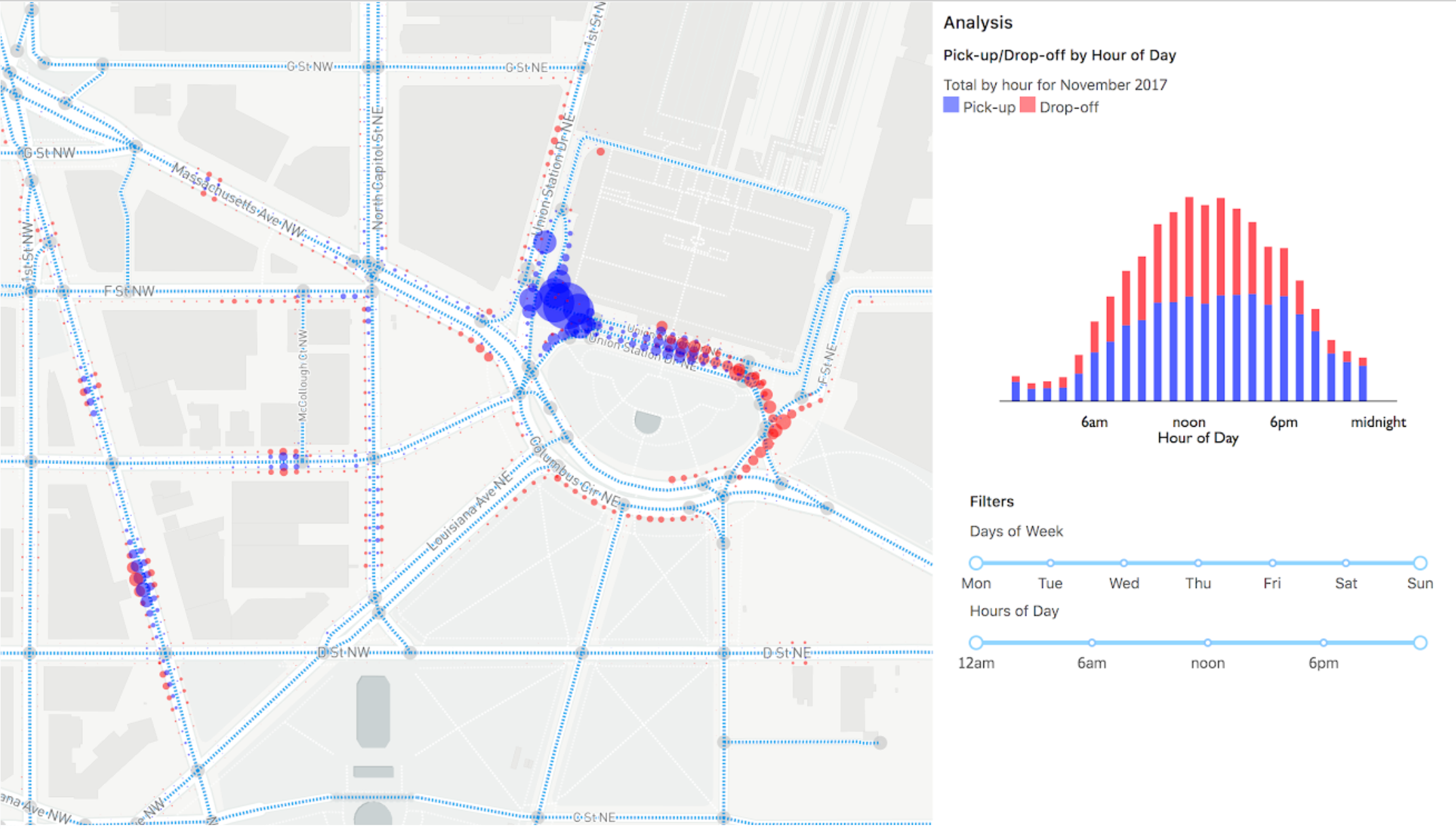
Using this method, dense point data can be binned and aggregated to describe overall street usage. The example below uses data for rideshare and taxi activity in Washington, DC. In this case, hotspots for pick-ups and drop-offs are shown. The data are binned into 10-meter intervals and visualized as proportional circles, offset to help illustrate the side of the road on which they took place. The data can also be analyzed based on particular time periods or other attributes.
Data can also be visualized along street segments. The example below shows speeds for roads in Bogotá, Colombia. To create this data, myriad GPS points have been transformed into street-linked, binned, and aggregated data.
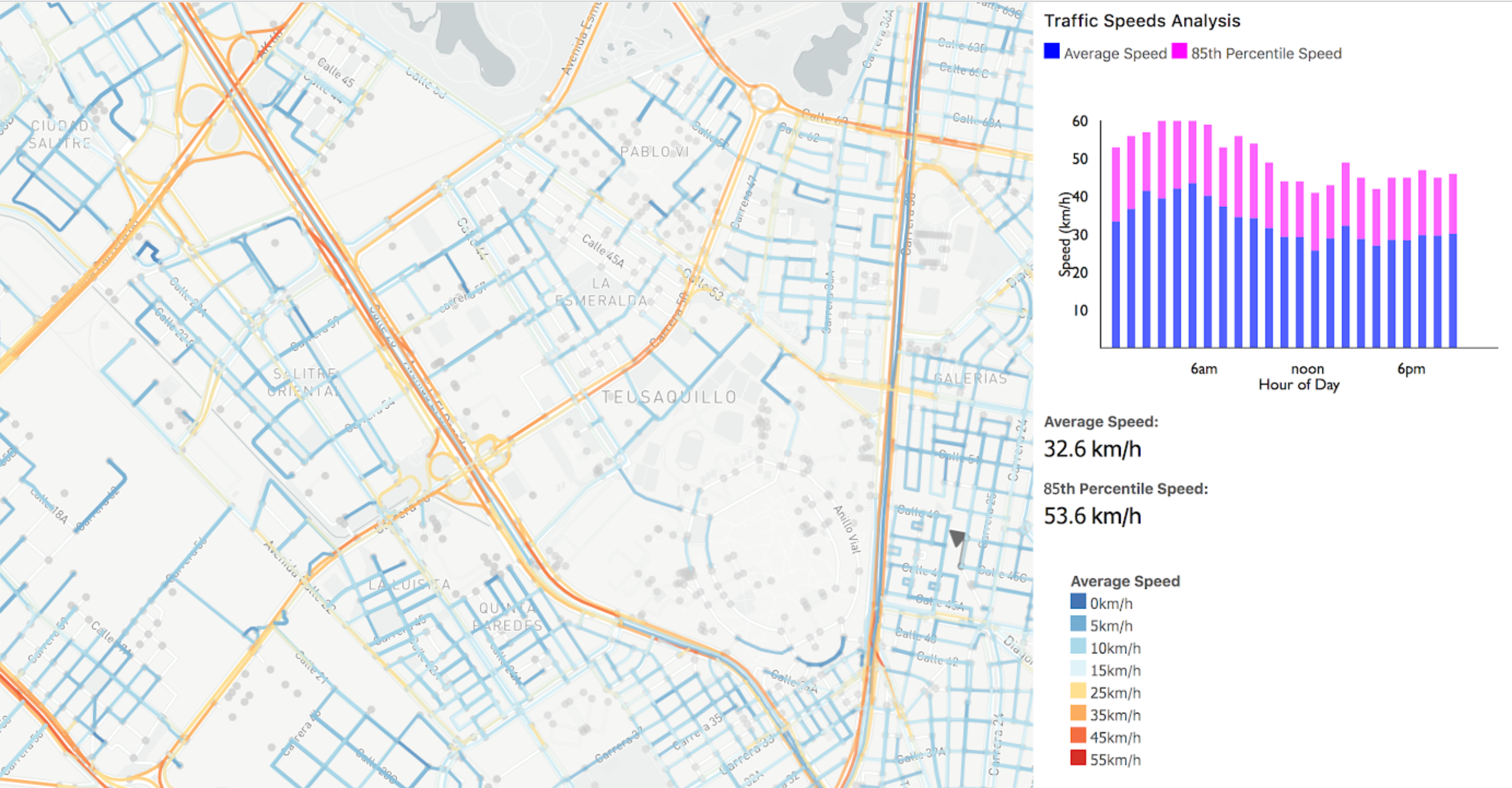
Through these methods, binning and aggregation enable users to take a deluge of raw data and turn it into meaningful metrics, like hourly scooter availability or average road speed or peak-hour TNC and taxi activity. These can be aggregated by street, street section, neighborhood, or other areas of interest.
Binning and aggregating offer an added benefit: privacy protection. Some raw data feeds, include data that describe individual trip locations. By aggregating sensitive data into total metrics for a given street or area, we avoid the need to store individualized trip data, reduce risk for cities, and protect individuals’ privacy - a core value of SharedStreets.


Get Involved
Do you work for a city or government agency? A private company? Or are you an independent researcher or developer? Learn how to start using the SharedStreets Toolkit.
Get Started